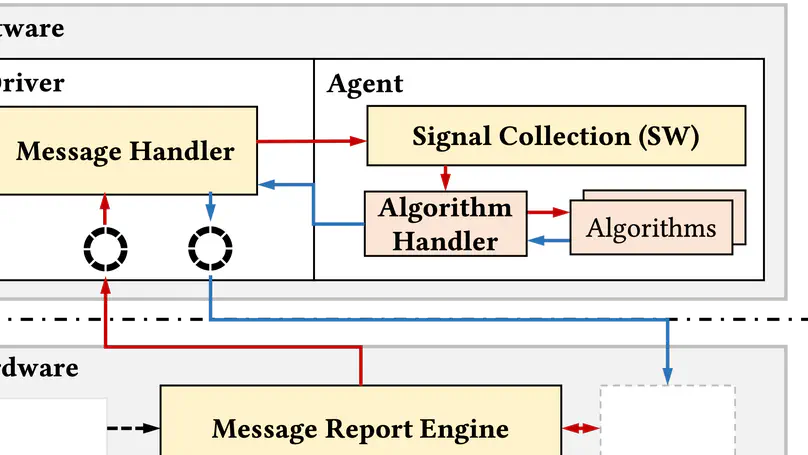
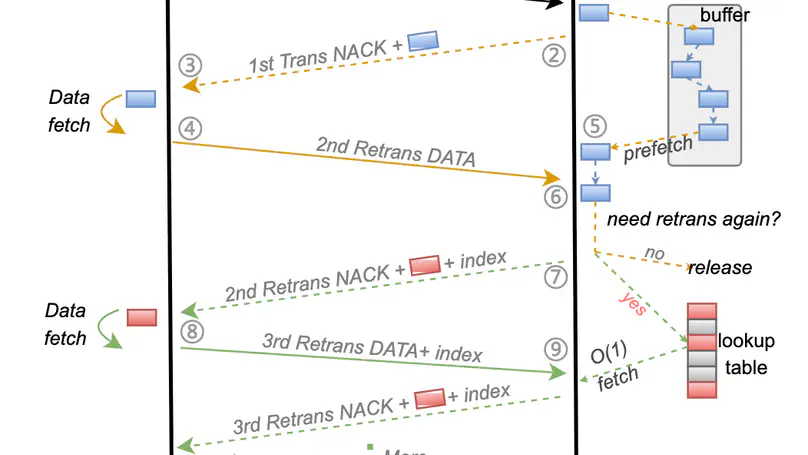
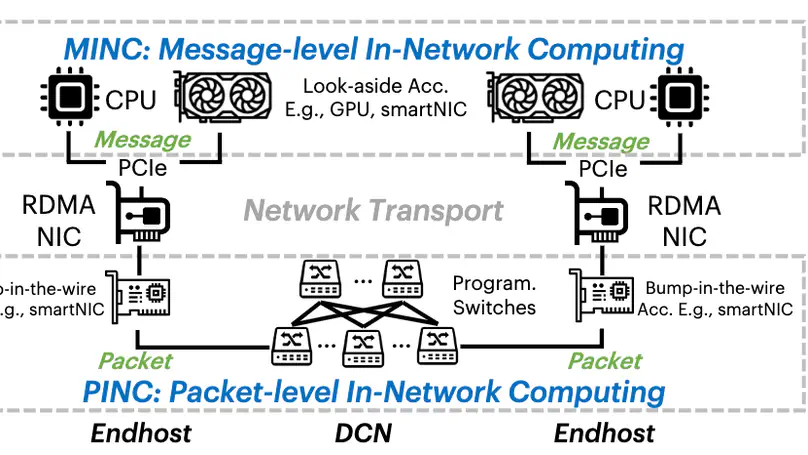
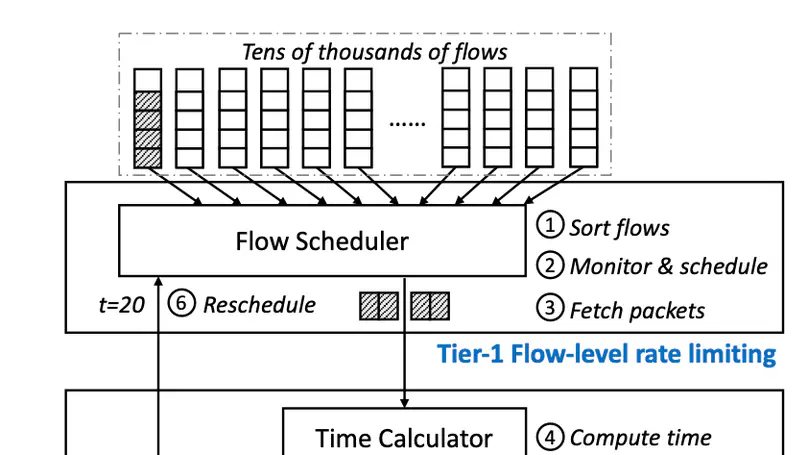
RDMA NICs desire a rate limiter that is accurate, scalable, and fast: to precisely enforce the policies such as congestion control and traffic isolation, to support a large number of flows, and to sustain high packet rates. Prior works such as SENIC and PIEO can achieve accuracy and scalability, but they are not fast enough, thus fail to fulfill the performance requirement of RNICs, due primarily to their monolithic de- sign and one-packet-per-sorting transmission. We present Tassel, a hierarchical rate limiter for RDMA NICs that can deliver high packet rates by enabling multiple-packet-per- sorting transmission, while preserving accuracy and scala- bility. At its heart, Tassel renovates the workflow of the rate limiter hierarchically: by first applying scalable rate limit- ing to the flows to be scheduled, followed by accurate rate limiting to the packets to be transmitted, while leveraging adaptive batching and packet filtering to improve the perfor- mance of these two steps. We integrate Tassel into the RNIC architecture by replacing the original QP scheduler module and implement the prototype of Tassel using FPGA. Exper- imental results show that Tassel delivers 125 Mpps packet rate, outperforming SENIC and PIEO by 3.6×, while sup- porting 16 K flows with low resource usage, 7.5% - 25.6% as compared to SENIC and PIEO, and preserving high accuracy, precisely enforcing rate limits from 100 Kbps to 100 Gbps.